
TL;DR
The threat hunting process that currently exists can be used in parallel with another process called indicator life cycle.
Both cycles are based on the same, aiming at proactive detection of threats and behaviors in corporate networks, leaving aside the reactive approach which is increasingly being avoided.
This is because traditional incident response processes have a methodology based on working on an event that has taken place, whereas the indicator lifecycle and threat hunting process work from the perspective of working to prevent something from happening.
During this blog I will explain the indicator lifecycle and how it can be used in parallel with the threat hunting process, also presenting a case study at the end.
Indicator life cycle
Indicator life cycle is not intended to define how long an indicator is valid or not, since this depends on a large number of variables not controlled by analysts.
The objective of this cycle is to proactively use certain indicators to mature them and then automate new searches that may reveal other related indicators.
Although the concept may initially seem a bit confusing, this cycle makes a lot of sense to apply it to threat hunting activities, as it is in these activities that maximum value can be derived.
Before going into detail about the explanation of this cycle, it is important to know what kind of indicators are valid for these operations, because nowadays, the term indicator is too ambiguous, not everyone understands the same thing by indicator.
Personally, I find the three differentiated concepts presented in the Lockheed Martin Corporation paper very useful. These concepts are as follows.
Atomic indicators: Atomic indicators are obtained based on the context of an intrusion that has taken place. The “problem” with this type of indicators is that they do not have to be exclusive activity of a specific adversary, i.e. an atomic indicator can be identified in several intrusions of different adversaries. Some examples of these indicators are IP addresses, domains, the name of a path of a domain…
Computed indicators: The concept of a calculated indicator is quite confusing. These indicators are developed from attributes that occur in an incident. For example, a hash of a file that has been seen in an incident can be calculated, so its MD5, SHA1… are calculated indicators. Another example could be a regular expression, which we can develop to detect something specific.
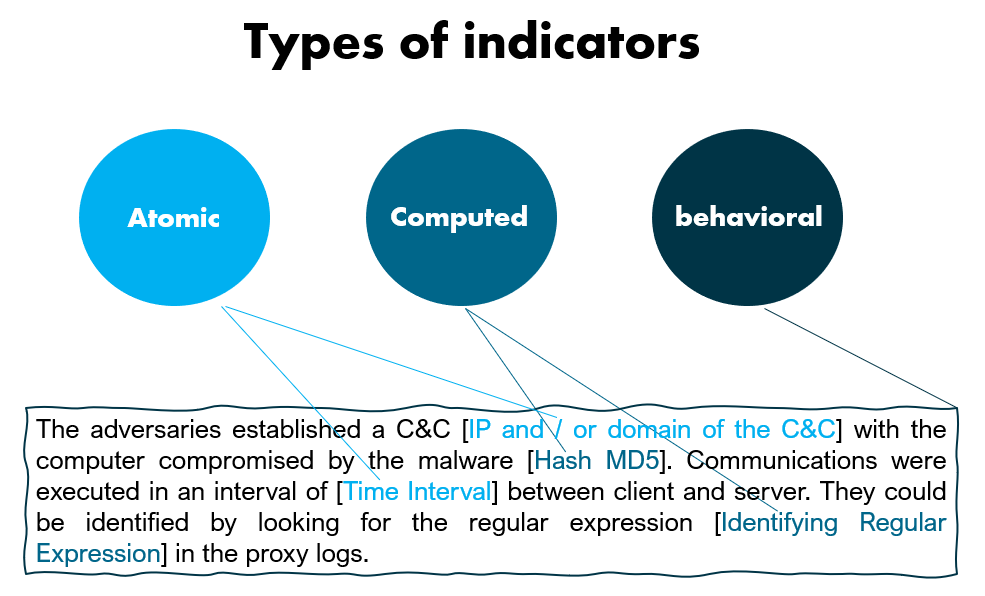
behavioral indicators: These indicators are composed of a combination of the two types described above. For example, within this category we could state the following; “Adversaries established a C&C [IP and/or C&C domain] with the machine compromised by the [MD5 Hash] malware. Communications were executed at an interval of [Time interval] between client and server. They could be identified by searching for the regular expression [Identifying regular expression] in the proxy logs.”
As you can imagine, this last type of indicator is the most valuable, as it has an associated context of what has happened and combines the atomic and calculated indicators. In addition, it is also easy to extract possible MITRE techniques and tactics to better understand what actions are being taken.
Now that we know the types of indicators that can be used in the indicator life cycle process, it is time to explain how the indicator life cycle works.
It consists of three main phases or stages, being the phases of developed, matured and used. In addition, this process is essential to involve people, processes and technology, which makes it really dynamic and useful in different operations, such as threat hunting.
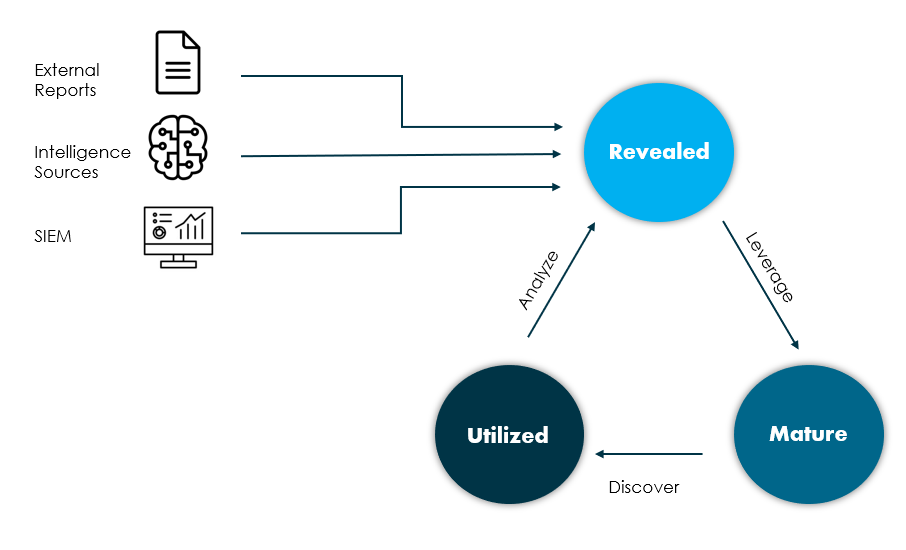
Applying this model to our threat hunting activities will provide us with the following capabilities:
- Generate internal threat intelligence
- Implement a stable pivoting process
- Identify new indicators from other indicators
From revealed to mature
This first phase has different sources as input. In the image above, some of the sources that could be a source of information to start the cycle are shown. For example, external (or internal) reports, intelligence sources, SIEM or any other monitoring tool, such as an IDS.
The above mentioned sources will carry with them indicators, which should be subjected to an examination, which will consist of historically searching our available internal data sources to see whether or not such an indicator was observed in the past ( see my post about collection management framework ). In case the result is positive, further investigation is required to determine whether the activity was malicious or not.
With a positive result, countermeasures for detection (in case the indicator becomes active again) and mitigation must be implemented internally, i.e., we not only want to detect but also actively prevent it from achieving its objectives.
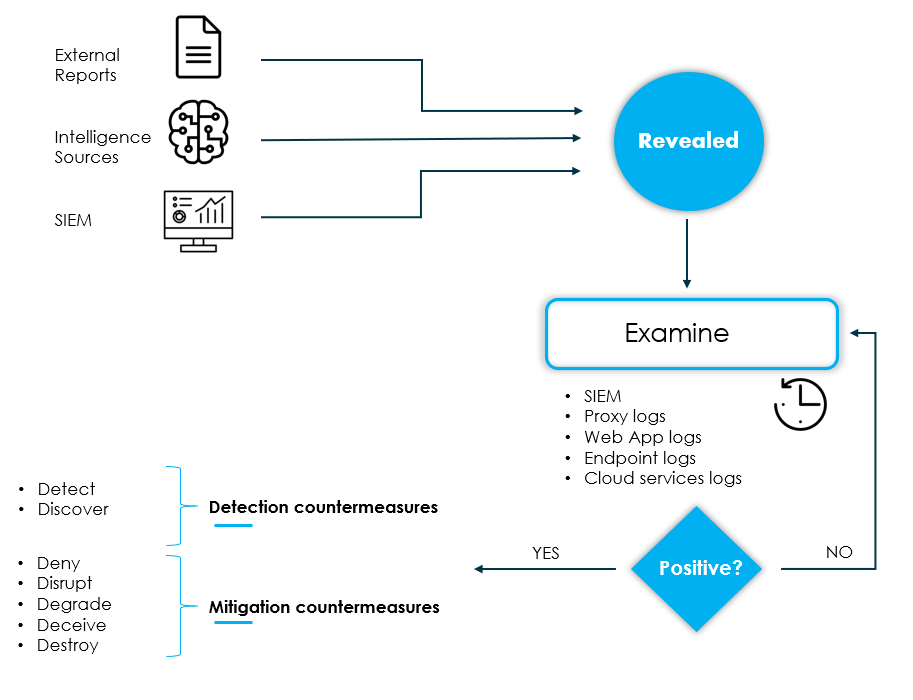
An indicator is considered mature when malicious activity has been retrospectively identified and detection and mitigation countermeasures have been implemented.
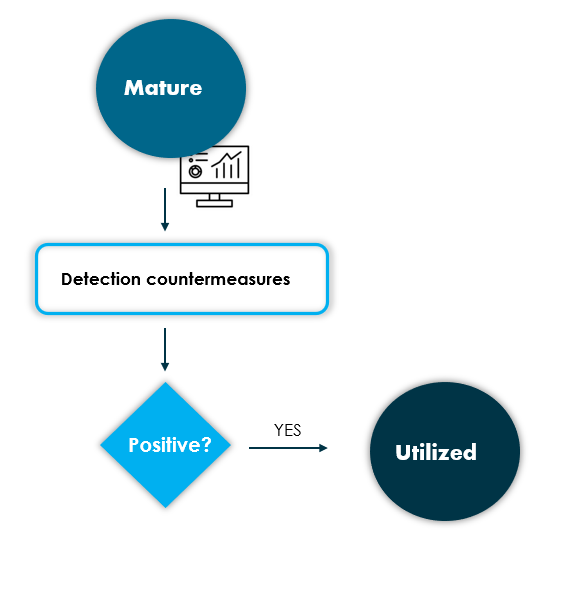
From mature to utilized
An indicator is utilized when the detection countermeasures are positive, i.e. the indicator has been identified by performing some action and is considered to have been used to detect a possible scenario that in principle should be malicious.
It is therefore important that the indicators have detection countermeasures in place, otherwise they can never be considered used, thus breaking the cycle completely and being unable to identify new indicators.
From utilized to revealed
This stage of the cycle requires a great deal of interaction from the analysts as they will have to carry out an analysis of the events that have been detected in the previous stage. The reason is simple, the indicator itself is only a small portion of what could be an intrusion or attempt, i.e., it will be necessary to investigate the whole context of what could be happening and build a complete picture of the operation that the adversaries are carrying out.
During this analysis, it is very likely that new indicators will appear that were not previously known, so these indicators will have to be moved to the disclosed state again to start the cycle.
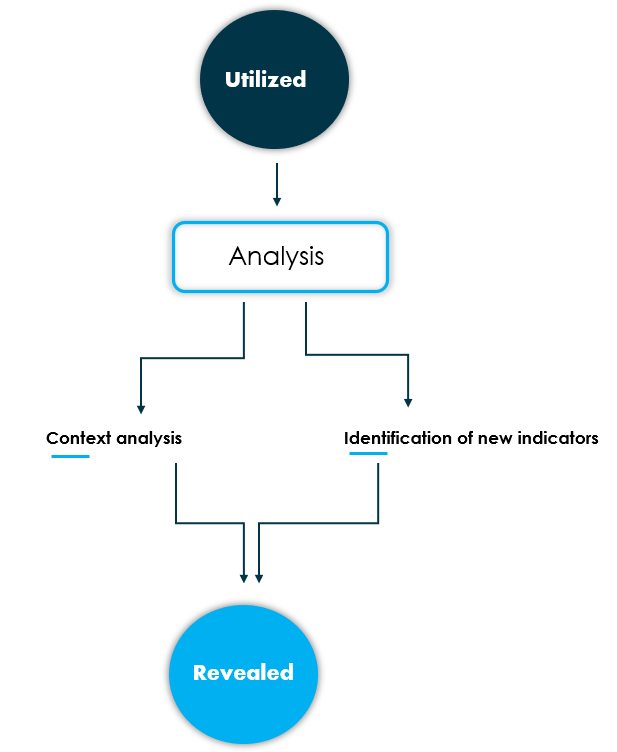
In those cases where a large number of new indicators are identified, or regardless of the quantity, quality should be prioritized. This means that there will be indicators that have more impact and more clearly detect malicious activity. An example could be a domain path, assuming that a malware communicates with baddomain.com/data?systeminfo=value, it is possible that we have seen another domain communicating with the same path, either because the malware incorporates several hardcoded domains in its code or any other reason, so it would be important to mature indicators to detect new behavior of other communications with /data?systeminfo=.
Applying the cycle in threat hunting activities
The entire life cycle of the indicators explained so far has a place in the famous threat hunting process, where the team first performs hypothesis generation by prioritizing the threats that could have the greatest impact on its activity. The next step is the pure hunting activity, where the other cycle can be implemented to structure the work even more and achieve objectives in a more effective way.
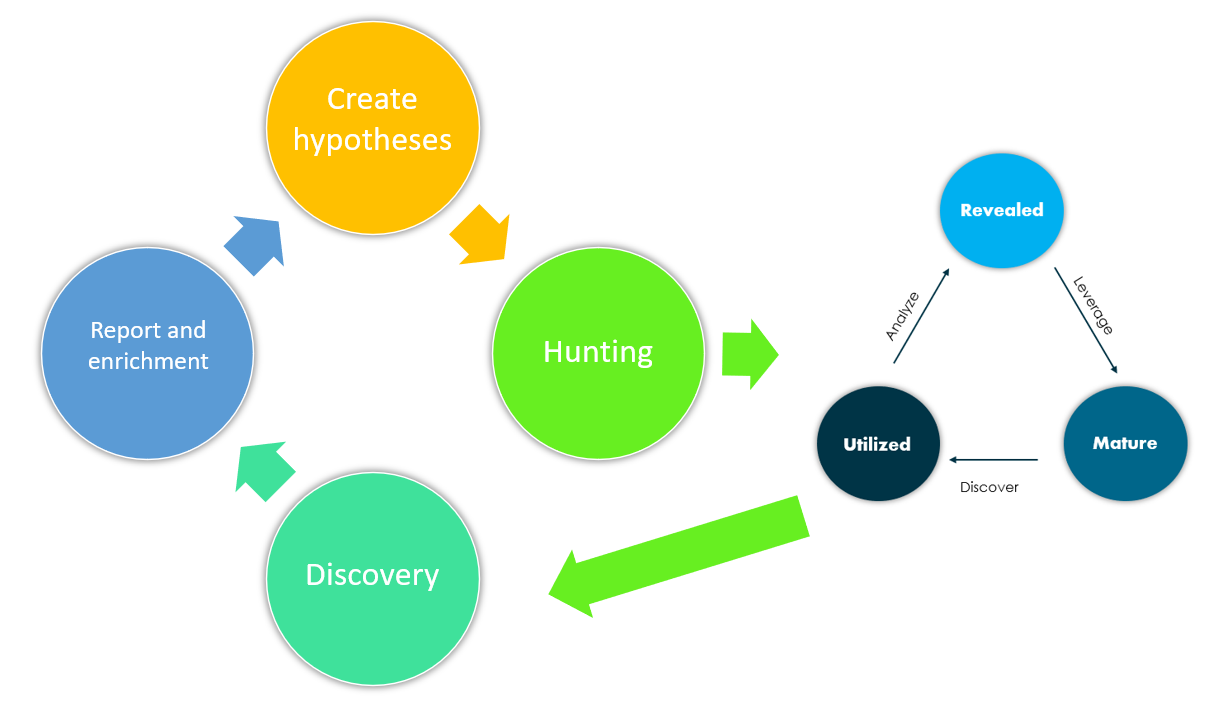
The discovery phase could also be framed within the life cycle of the indicators, more specifically with the mature stage, which would be those cases where some past behavior has been detected with the hunt being carried out by the team.
Case study
Let’s imagine that we are generating different scenarios internally to carry out hunting activities.
#1 — Hypothesis generation
We are interested in identifying the creation of scheduled tasks in the systems in the past, because an adversary who has special motivation in our company’s sector could materialize an incident.
Objective: Identify suspicious scheduled tasks in the systems.
Searches: Windows events 4698 and 4702.
#2 - Hunting
The team begins to perform threat hunting activities on the systems using whatever technology is available, be it EDR consoles, opensource tools, SIEM, etc…
A positive is identified in a system, where a scheduled task is checked.
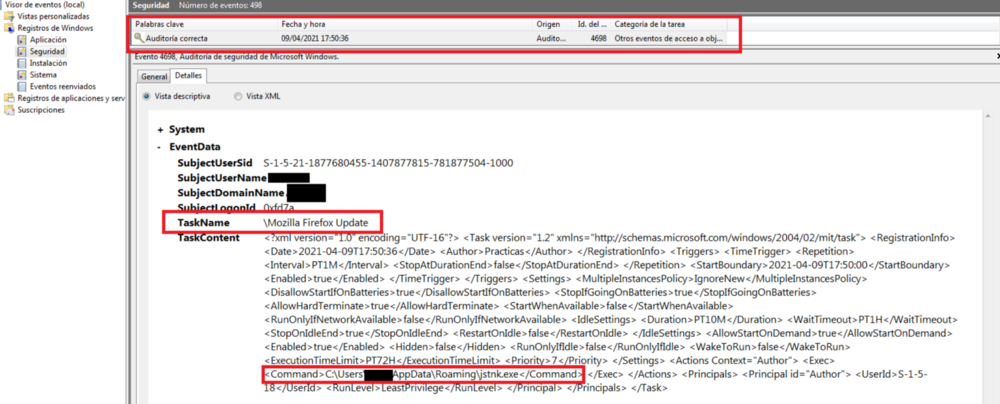
#3 - Revealed to mature
The finding in this case can be verified as a scheduled task masked with a name of “Mozilla Firefox Update” has been enabled by launching via command line a file named “jstnk.exe” found in the AppData directory.
At this point we would have two indicators, a calculated one and a behavioral one.
Computed indicator: MD5 hash of the file jstnk.exe
behavioral Indicator: An adversary sets the scheduled task “Mozilla Firefox Update” (T1053.005) which executes the file jstnk.exe [MD5].
With both indicators, it is necessary to check retrospectively whether similar persistence has been performed on other systems in the corporate network, either with the same malware called jstnk.exe or using the same scheduled task technique.
If new computers are detected where persistence has been performed using T1053.005, countermeasures for detection and mitigation are therefore implemented.
Detection countermeasures: Execution of the command “schtasks /create “, focusing on files referenced in Appdata. A sigma rule similar to the following might be helpful -> https://github.com/SigmaHQ/sigma/blob/master/rules/windows/process_creation/win_susp_schtask_creation.yml
Mitigation countermeasures: Establish a policy to limit the use of schtasks in the system.
#4 - Mature to utilized
In this case, let’s imagine that the detection countermeasure mentioned above has worked, and new findings of scheduled task creation are appearing on other systems.
These detections therefore mean that the indicator has been utilized.
#5 - Utilized to revealed
Analysts are starting to conduct research for alerts that have tested positive for creating scheduled tasks. What this triggers is that, it is becoming evident that the malware used for the persistence of this technique is different in all cases, but when the behavior is analyzed, many of the samples share infrastructure for communication with the C&Cs.
All these new indicators will go through the life cycle again to automate new detections and behaviors that may be related to the hunting being performed.
#6 — Discovery
As the findings are aligned with the hypotheses that were generated in the first step, this stage of the threat hunting process means that as much information about the TTPs that have been used at a low level as possible will need to be collected in order to automate or document the findings.
#7 — Report and enrichment
Finally, the threat hunting process requires automating as much as possible the hunt mission carried out, so that the team does not waste time running the same mission every X amount of time and can focus their efforts on developing new missions for other techniques that may be being used in the corporate networks.
Twitter: https://twitter.com/Joseliyo_Jstnk
LinkedIn: https://www.linkedin.com/in/joseluissm/